Abstract
Personalized diagnosis by cached solutions with hypertension as a study model
Author(s): P.C. Carvalho, S.S. Freitas, A.B. Lima, M. Barros, I. Bittencourt, W. Degrave, I. Cordovil, R. Fonseca, M.G.C. Carvalho, R.S. Moura Neto and P.H. CabelloStatistical modeling of links between genetic profiles with environmental and clinical data to aid in medical diagnosis is a challenge. Here, we present a computational approach for rapidly selecting important clinical data to assist in medical decisions based on personalized genetic profiles. What could take hours or days of computing is available on-the-fly, making this strategy feasible to implement as a routine without demanding great computing power. The key to rapidly obtaining an optimal/nearly optimal mathematical function that can evaluate the “dis-ease stage” by combining information of genetic profiles with personal clinical data is done by querying a precomputed solution database. The database is previously generated by a new hybrid feature selection method that makes use of support vector machines, recursive feature elimination and random sub-space search. Here, to evaluate the method, data from polymorphisms in the renin-angiotensin-aldosterone system genes together with clinical data were obtained from patients with hypertension and control subjects. The disease “risk” was determined by classifying the patients’ data with a support vector machine model based on the optimized feature; then measuring the Euclidean distance to the hyperplane decision function. Our results showed the association of reninangiotensin- aldosterone system gene haplotypes with hypertension. The association of polymorphism patterns with different ethnic groups was also tracked by the feature selection process. A demonstration of this method is also available online on the project’s web site.
Impact Factor an Index

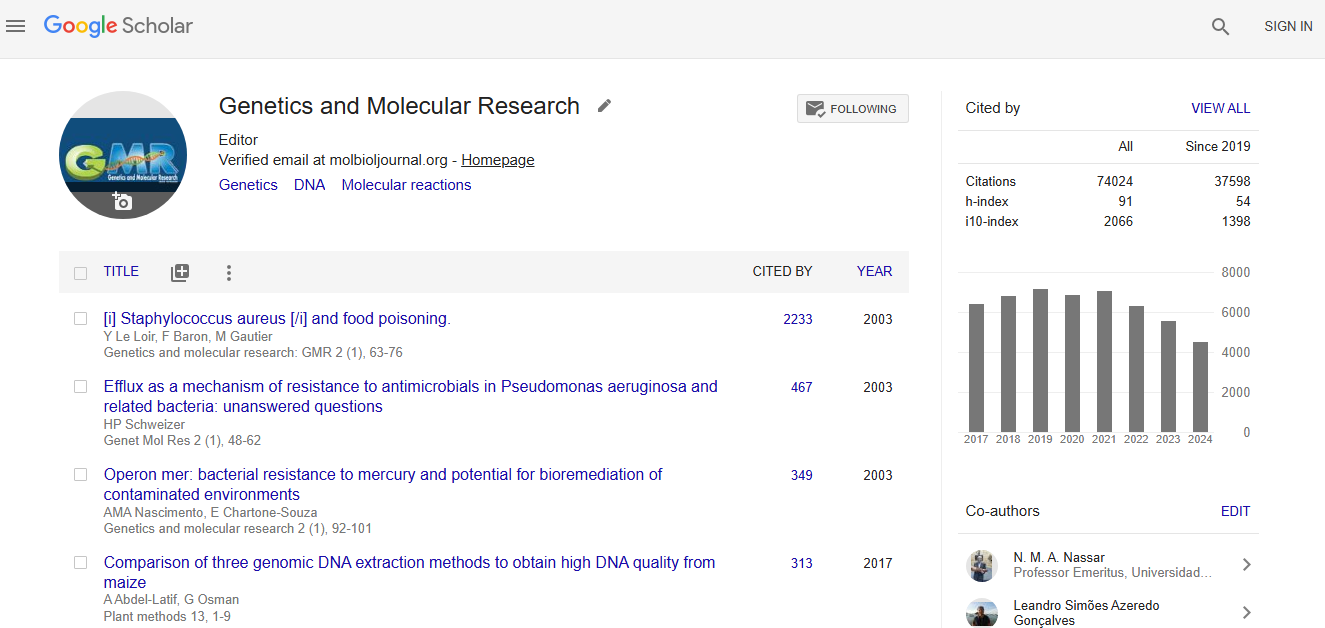
Google scholar citation report
Citations : 74024
Genetics and Molecular Research received 74024 citations as per google scholar report